Cómo mejorar el reconocimiento OCR
En términos sencillos, la herramienta OCR realiza una llamada a un modelo para detectar información de un documento o imagen. Sin embargo, no es infalible. Existen diferentes métodos para aumentar su fiabilidad y eficiencia.
La herramienta sigue estos pasos:
- Convertir a imagen: Si la entrada es un PDF, se convierte en una imagen. Si ya es una imagen, continúa directamente.
- Búsqueda de referencias: Busca imágenes de referencia en la base de conocimiento del agente (si hay alguna configurada).
- Llamada al LLM: Llama a un modelo LLM usando un prompt (el parámetro
questionde la herramienta OCR), que especifica exactamente qué debe reconocer y extraer el modelo.
Uso de un modelo específico
Por defecto, la herramienta utiliza un modelo configurado en el archivo gradle.properties. Sin embargo, se recomienda encarecidamente configurar un modelo específico para el agente que utilizará la herramienta, para garantizar el mejor rendimiento en tareas visuales.
En la ventana Agente, en la pestaña Habilidades y herramientas, puede especificar un Modelo para la herramienta OCR. Este campo le permite sobrescribir el modelo por defecto para esa herramienta específica en ese agente.
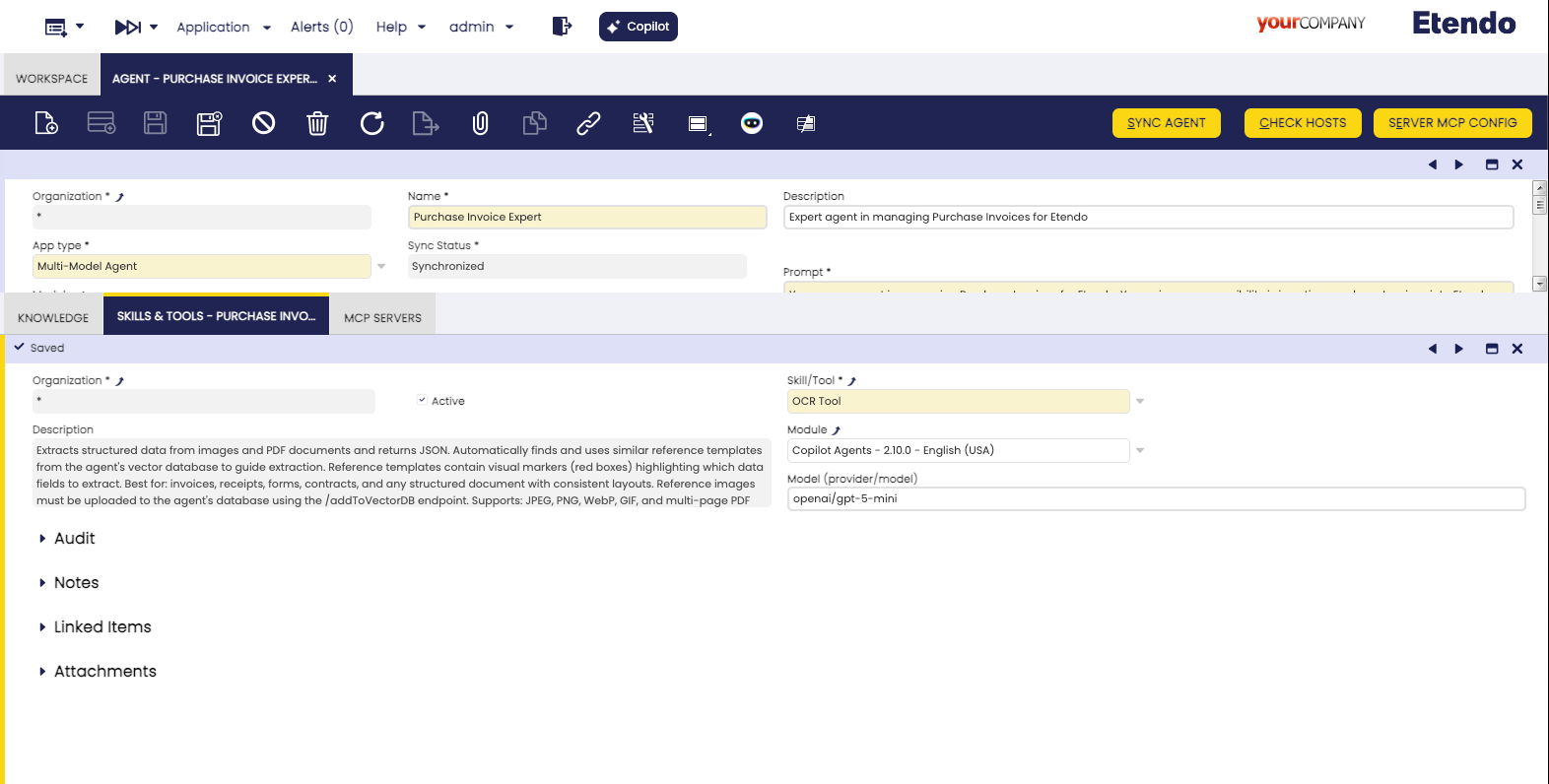
- Formato: El modelo debe especificarse usando el formato
provider/modelname(p. ej.,openai/gpt-5-mini). - Recomendación: Use modelos con sólidas capacidades de visión. Con frecuencia se publican nuevos modelos con mayor precisión de reconocimiento y velocidades de procesamiento más rápidas, por lo que es aconsejable mantenerse actualizado con las últimas versiones disponibles.
Info
El campo Modelo solo aparece en la pestaña Habilidades y herramientas si la herramienta tiene habilitada la casilla Usar modelo en la ventana Habilidad/Herramienta.
Uso de un prompt fijo
En general, cuando el agente llama a la herramienta OCR, envía una question (prompt) sobre lo que necesita reconocer. El agente construye esta pregunta de forma dinámica en función del contexto y las necesidades actuales. Sin embargo, generar esta pregunta cada vez puede provocar inconsistencias entre ejecuciones.
Para evitarlo, puede "fijar" el prompt para la herramienta OCR indicando al agente exactamente qué pregunta debe usar.
- Cómo hacerlo: En el prompt del agente, especifique las instrucciones exactas para la herramienta OCR. Por ejemplo: "Al llamar a la herramienta OCR, use esta pregunta: 'Lea el nombre del producto, las cantidades, el impuesto utilizado y el importe total del recibo'".
- Beneficio: Al fijar la pregunta, se asegura de que la herramienta OCR reciba siempre las mismas instrucciones, haciendo que el proceso de extracción sea más predecible. Además, cualquier mejora realizada en esta pregunta fija impactará positivamente en todas las ejecuciones.
Aumentar los DPI
Cuando el archivo de entrada es un PDF, la herramienta OCR debe renderizarlo en una imagen antes de procesarlo. Esta calidad de conversión está controlada por un parámetro llamado scale.
- Lógica del valor por defecto: La escala por defecto es
3.0, lo que corresponde aproximadamente a 300 DPI. - Cómo aumentarlo: Para mejorar el reconocimiento de texto muy pequeño o diseños extremadamente complejos, puede aumentar la calidad de renderizado indicando al agente en su prompt. Por ejemplo, puede añadir: "Use una escala de 4.0 al usar OCRTool" para lograr 400 DPI.
Los valores de escala más altos proporcionan mejor calidad y una extracción más precisa, pero también dan como resultado tamaños de imagen mayores y tiempos de procesamiento más lentos.
Uso de salida estructurada
OCRTool admite salida estructurada, lo que le permite definir un esquema JSON específico que el modelo debe seguir al extraer información. Esto garantiza que la salida sea siempre consistente y fácil de procesar por otras herramientas o sistemas.
Para usar salida estructurada, debe:
- Definir el esquema: Cree un archivo Python en el directorio
tools/schemas/ubicado en la raíz de su módulo Copilot (p. ej.,modules/my_module/tools/schemas/mail.py). El nombre del archivo será el nombre del esquema (p. ej.,mail.py). - Implementar el modelo Pydantic: Dentro del archivo, defina una clase que herede de
pydantic.BaseModel. El nombre de la clase debe seguir el patrón<SchemaName>Schema(p. ej.,class MailSchema(BaseModel):). - Invocar la herramienta: Especifique el nombre del esquema en el parámetro
structured_outputal llamar a OCRTool.
Ejemplo: crear un esquema "Mail"
Suponga que quiere extraer información de correos electrónicos o cartas escaneadas. Puede crear un esquema llamado Mail:
Archivo: tools/schemas/mail.py
from typing import List, Optional
from pydantic import BaseModel, Field
# Internal model for nested data
class MailAttachment(BaseModel):
filename: str = Field(description="Name of the attachment file")
size: Optional[int] = Field(description="Size of the file in bytes")
# Main schema class - Must end with 'Schema'
class MailSchema(BaseModel):
"""Schema for extracting email/mail information."""
sender: str = Field(description="The person or entity who sent the mail")
recipient: str = Field(description="The person or entity who received the mail")
subject: Optional[str] = Field(description="The subject line of the mail")
body: str = Field(description="The main content or body of the mail")
date: Optional[str] = Field(description="The date when the mail was sent")
attachments: List[MailAttachment] = Field(default_factory=list, description="List of attachments mentioned")
Una vez definido, puede indicar al agente que use este esquema:
- Prompt del agente: "Cuando extraiga información de una imagen de correo electrónico, use OCRTool con la salida estructurada 'Mail'."
La herramienta carga dinámicamente el esquema desde el archivo. Convierte el valor de structured_output (p. ej., Mail) a minúsculas para encontrar el archivo (mail.py) y luego busca la clase MailSchema.
La extracción resultante seguirá la estructura exacta de su MailSchema, lo que la hace altamente fiable para flujos de trabajo automatizados.
Añadir datos de referencia
La herramienta OCR incluye un sistema de referencias inteligente que busca automáticamente plantillas de documentos similares en la base de conocimiento del agente. Cuando se encuentra una referencia similar, guía el proceso de extracción indicando qué campos de datos extraer mediante marcadores visuales.
Para añadir datos de referencia:
- Preparar la referencia: Tome una imagen de alta calidad del tipo de documento (p. ej., la factura de un proveedor específico). Si es posible, resalte los campos clave que deben extraerse (p. ej., importe total, impuesto, fecha) usando recuadros de colores o indicaciones.
- Subir a la base de conocimiento: En la ventana Archivo de base de conocimiento, suba la imagen.
- Indexar la imagen: Asegúrese de que el archivo esté sincronizado con el agente. El sistema lo indexará automáticamente en una base de datos de imágenes separada diseñada para la búsqueda de similitud visual.
- Coincidencia automática: Cuando el agente procese un documento nuevo, la herramienta OCR buscará automáticamente la referencia más similar en esta base de datos para mejorar la precisión de la extracción.
Ejemplo: mejorar la detección de tercero en Purchase Invoice Expert
Si quiere mejorar la detección del tercero (BP) para un formato de factura específico, puede añadir una imagen de referencia de esa factura a la base de conocimiento del agente. En esta imagen, debe marcar las secciones donde se encuentra la información del BP. Esto guía a la herramienta OCR para que busque en esas áreas específicas cuando encuentre un diseño de factura similar, aumentando significativamente la fiabilidad de la extracción.
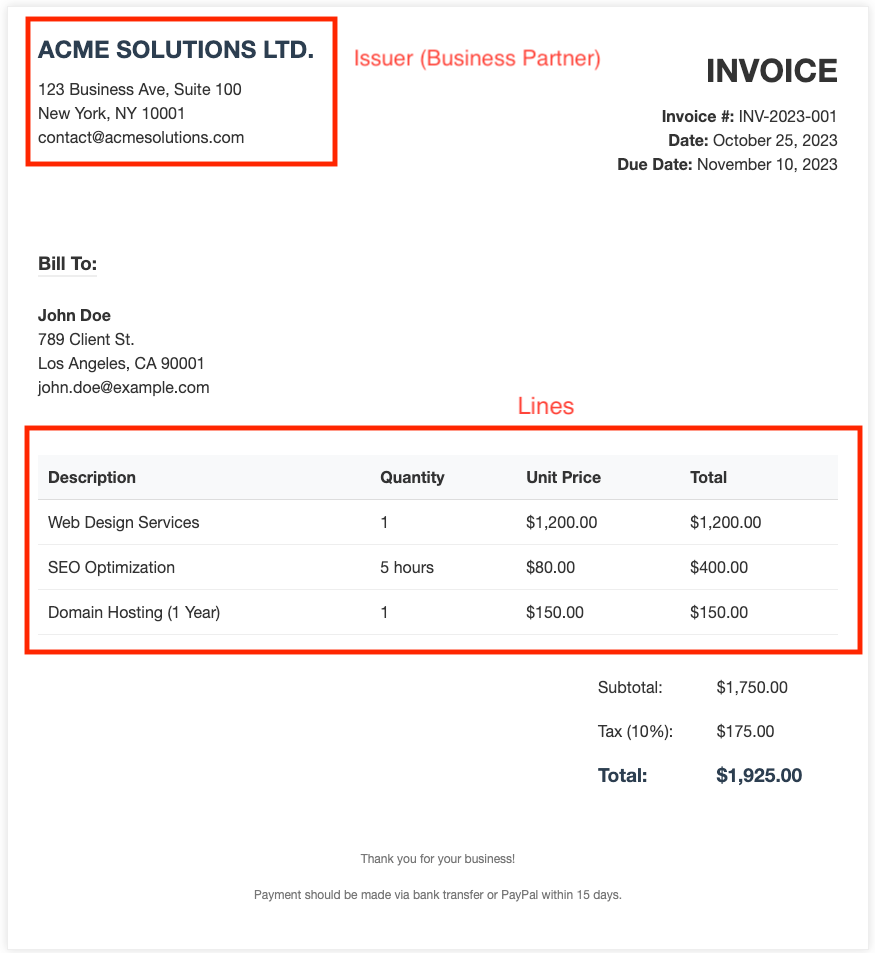
Campos marcados en la imagen de referencia para guiar la extracción OCR.
Tip
El uso de plantillas de referencia es especialmente útil para documentos con diseños no estándar, donde el LLM podría tener dificultades para localizar campos específicos.
Tip
Si no quiere usar imágenes de referencia para una ejecución específica, puede deshabilitar esta funcionalidad indicando en el prompt del agente: "Al usar OCRTool, no use imágenes de referencia de la base de conocimiento.". El agente deshabilitará la búsqueda de referencias para esa ejecución mediante un parámetro de la herramienta OCR.