Herramienta de reconocimiento óptico de caracteres (OCR)
Paquete Java: com.etendoerp.copilot.toolpack
Visión general
La herramienta de reconocimiento óptico de caracteres (OCR) es una herramienta avanzada que extrae datos estructurados de imágenes y documentos PDF. Utiliza modelos de IA de visión para reconocer y extraer texto, con soporte para la coincidencia automática de plantillas de referencia, esquemas de salida estructurada y configuración multiproveedor.
Características principales:
- Coincidencia automática de referencias: busca plantillas de referencia similares en la base de datos vectorial del agente para guiar la extracción con marcadores visuales
- Esquemas de salida estructurada: admite esquemas predefinidos (testdocument, etc.) y esquemas personalizados extensibles
- Soporte multiformato: archivos JPEG, PNG, WebP, GIF y PDF multipágina
- Soporte multiproveedor: compatible con modelos de OpenAI (GPT-4o, GPT-5-mini) y Gemini
- Configuración avanzada: configuración del modelo por agente, control de calidad de PDF y filtrado por umbral
Info
Para poder incluir esta funcionalidad, debe estar instalado el Copilot Extensions Bundle. Para ello, siga las instrucciones del marketplace: Copilot Extensions Bundle. Para más información sobre las versiones disponibles, la compatibilidad con el core y las nuevas funcionalidades, visite Copilot Extensions - Notas de la versión.
Funcionalidad
Esta herramienta automatiza el proceso de extracción de texto de archivos basados en imágenes o PDFs. Esto puede ser especialmente útil para tareas como la digitalización de documentos, la extracción de datos y el análisis de contenido.
Las Características avanzadas de la herramienta OCR permiten aprovechar plantillas de referencia y esquemas de salida estructurada, mejorando la precisión y la consistencia de los datos extraídos.
Cuando se invoca la herramienta, procesa la imagen o el archivo PDF proporcionado, busca plantillas de referencia similares si están disponibles y extrae la información relevante en función de la pregunta o las instrucciones especificadas.
Filtrado por umbral: la herramienta puede filtrar las plantillas de referencia en función de un umbral de similitud configurable (configurado en el archivo gradle.properties), como una puntuación mínima de coincidencia. Esto garantiza que solo se utilicen referencias con una coincidencia estrecha para la extracción, mejorando la precisión. Este umbral puede deshabilitarse si es necesario, lo que permite que la herramienta utilice siempre la mejor coincidencia encontrada independientemente del nivel de similitud.
El uso de esta herramienta consta de las siguientes acciones:
-
Recepción de parámetros:
La herramienta recibe un objeto de entrada que contiene los siguientes parámetros:
-
path (obligatorio): la ruta absoluta o relativa del archivo de imagen o PDF que se va a procesar. El archivo debe existir en el sistema de archivos local.
-
question (obligatorio): una pregunta contextual o instrucciones que especifican la información que se debe extraer de la imagen. Sea preciso sobre los campos de datos necesarios (p. ej., «Extraiga el número de factura, la fecha, el importe total y el nombre del proveedor»). Unas instrucciones claras mejoran la precisión de la extracción.
-
structured_output (opcional): especifique un nombre de esquema para utilizar el formato de salida estructurada (p. ej., «testdocument»). Los esquemas disponibles se cargan desde el directorio
tools/schemas/. Cuando se especifica, la respuesta seguirá la estructura del esquema predefinido. Déjelo vacío para una extracción JSON no estructurada. -
scale (opcional): factor de escala de renderizado del PDF (p. ej., 2.0 = ~200 DPI, 3.0 = ~300 DPI). Los valores más altos proporcionan mejor calidad, pero mayor tamaño y un procesamiento más lento. Valor por defecto: 2.0.
-
disable_threshold_filter (opcional): Valor por defecto:
false. Cuando estrue, ignora el umbral de similitud configurado y devuelve la referencia más similar encontrada en la base de datos del agente (deshabilita el filtrado por umbral). En otras palabras, la herramienta utilizará siempre la mejor coincidencia encontrada, independientemente de lo diferente que pueda ser del documento original. -
force_structured_output_compat (opcional): Valor por defecto:
false. Modifica el método de comunicación para las solicitudes de salida estructurada. Por defecto es false (utiliza el sistema nativo de salida estructurada). Cuando estrue(o automáticamente para modelos que empiezan por «gpt-5»), cambia cómo se envía la entrada estructurada al LLM, omitiendo el envoltorio nativo de salida estructurada e incrustando el JSON del esquema directamente en el prompt del sistema. Esto garantiza la compatibilidad con agentes antiguos, requisitos específicos del modelo o para resolver problemas de compatibilidad. Úselo solo cuando sea necesario.
Tip
Para aprender cómo optimizar los resultados de esta herramienta, consulte la guía Cómo mejorar el reconocimiento OCR.
-
-
Obtención del archivo: la herramienta recupera el archivo especificado en el parámetro path. Verifica la existencia del archivo y garantiza que esté en un formato compatible (
JPEG,JPG,PNG,WEBP,GIF,PDF). -
Conversión de PDF: si el archivo de entrada es un
PDF, se convierte a un formato de imagen (JPEG) utilizando la biblioteca pypdfium2. Cada página delPDFse renderiza como una imagen independiente. -
Conversión de imagen: otros formatos de imagen se procesan directamente o se convierten a
JPEGsi es necesario. -
Procesamiento de imagen: la imagen se procesa utilizando un modelo de IA de visión (OpenAI GPT o Google Gemini, según la configuración). Este modelo interpreta el texto dentro de la imagen y extrae la información relevante en función de la question proporcionada.
-
Devolución del resultado: la herramienta devuelve un objeto JSON que contiene la información extraída de la imagen o del PDF.
Características avanzadas
Coincidencia automática de plantillas de referencia
La herramienta OCR incluye un sistema de referencias inteligente que busca automáticamente plantillas de documentos similares en la base de datos vectorial del agente. Cuando se encuentra una referencia similar, guía el proceso de extracción indicando qué campos de datos extraer.
Cómo funciona:
- Al procesar un documento, la herramienta busca en la base de datos vectorial del agente (ChromaDB) imágenes de referencia similares.
- Las imágenes de referencia contienen marcadores visuales (recuadros rojos) que resaltan los campos de datos relevantes a extraer.
- La herramienta utiliza la referencia como plantilla para priorizar y extraer los mismos campos del documento actual.
- Esto mejora significativamente la precisión de extracción para documentos con diseños consistentes (facturas, recibos, formularios).
Gestión de imágenes de referencia:
- Cargue imágenes de referencia en la base de conocimiento del agente como lo haría normalmente con cualquier otro documento.
- Las imágenes de referencia deben tener marcadores visuales (normalmente recuadros rojos) que indiquen los campos de datos.
- Cada agente mantiene su propia base de datos vectorial de plantillas de referencia.
- El umbral de similitud se puede controlar o desactivar mediante el parámetro
disable_threshold_filter.
Cuándo usar referencias:
- Procesamiento de facturas, recibos o formularios con diseños consistentes.
- Cuando necesite extraer campos específicos repetidamente de documentos similares.
- Para mejorar la precisión de extracción proporcionando guía visual.
Regulación del umbral de similitud:
El umbral de similitud determina en qué medida un documento debe coincidir con una plantilla de referencia para que se utilice. Esto se controla mediante una propiedad en el archivo gradle.properties:
- Propiedad:
copilot.reference.similarity.threshold - Métrica: utiliza distancia L2 (valores más bajos son más estrictos, valores más altos son más flexibles).
- Rango recomendado:
0.15a0.30.
Comportamiento por defecto (listo para usar):
Por defecto, la herramienta está configurada para ser altamente permisiva:
- Si la propiedad
copilot.reference.similarity.thresholdno está configurada, la herramienta no aplica ningún filtrado por distancia. - Buscará automáticamente la referencia más similar en la base de datos y siempre utilizará la mejor coincidencia encontrada, independientemente de lo diferente que pueda ser respecto al documento original.
- Esto garantiza que, si solo tiene una plantilla de referencia, la herramienta siempre intentará utilizarla.
Cómo especificar o desactivar el umbral:
- Para especificar un umbral: configure la propiedad
copilot.reference.similarity.thresholden el archivogradle.propertiescon un valor float (p. ej.,0.20). Esto evitará que la herramienta utilice referencias que sean demasiado diferentes. - Para desactivar el filtrado por umbral: si tiene un umbral configurado pero quiere ignorarlo para una solicitud específica, configure el parámetro
disable_threshold_filteratrueen la entrada de la herramienta. Esto forzará a la herramienta a usar la referencia más similar encontrada, aunque no sea una coincidencia cercana. Esto puede hacerse indicando al agente que desactive el umbral en su prompt. El agente entonces pasará el parámetro a la herramienta.
Esquemas de salida estructurada
La herramienta admite esquemas predefinidos que imponen una estructura de salida específica. Esto es útil cuando necesita formatos de datos consistentes para el procesamiento posterior.
Esquemas disponibles:
Los esquemas se almacenan en el directorio tools/schemas/ y pueden ampliarse con esquemas personalizados. En Copilot Extensions se incluye un esquema de ejemplo:
- testdocument: esquema integral de documento de prueba con varios tipos de campo (fechas, importes, líneas, dirección, etc.).
- Se pueden añadir esquemas personalizados creando nuevos archivos de esquema en el directorio de esquemas.
Tip
Para aprender a crear y usar esquemas personalizados de salida estructurada, consulte la guía Cómo mejorar el reconocimiento OCR.
Uso:
{
"path": "/home/user/document.pdf",
"question": "Extract the information from this document",
"structured_output": "testdocument"
}
La herramienta devolverá los datos siguiendo la estructura exacta definida en el esquema, garantizando la consistencia en todas las extracciones.
Modo de compatibilidad:
Para modelos o agentes antiguos que no admiten salida estructurada nativa, utilice el parámetro force_structured_output_compat. Esto cambia cómo se envía la entrada estructurada al LLM, incrustando el JSON del esquema directamente en el prompt del sistema:
{
"path": "/home/user/document.pdf",
"question": "Extract the information from this document",
"structured_output": "testdocument",
"force_structured_output_compat": true
}
Configuración multiproveedor
La herramienta OCR admite múltiples proveedores de IA con opciones de configuración flexibles:
Proveedores compatibles:
- OpenAI: modelos como
gpt-4o,gpt-5-mini(valor por defecto:openai/gpt-5-mini) - Gemini: modelos de visión Gemini de Google
Métodos de configuración (por orden de prioridad):
-
Configuración global (gradle.properties): configure
copilot.ocrtool.modelpara establecer el modelo globalmente para todos los agentes. Esta propiedad actúa como una anulación global; si está definida, la herramienta utilizará este modelo para todas las solicitudes OCR, omitiendo cualquier configuración por agente.Para configurarlo, añada la propiedad a su archivo
La herramienta infiere automáticamente el proveedor en función de cómo empieza el nombre del modelo (p. ej., los modelos que empiezan porgradle.propertiesespecificando el nombre del modelo:geminiusarán el proveedor Gemini; en caso contrario, se usa OpenAI). -
Configuración por agente: configure el modelo en la pestaña Habilidades y herramientas de la ventana Agente usando el campo Modelo. El modelo debe especificarse con el formato
provider/modelname(p. ej.,openai/gpt-4o,google/gemini-1.5-pro). Esto permite que distintos agentes utilicen distintos modelos para la misma herramienta. -
Valor por defecto: si no se proporciona ninguna configuración, se utiliza
openai/gpt-5-minicon el proveedor OpenAI.
Detección del proveedor:
El proveedor se detecta automáticamente en función del nombre del modelo:
- Los modelos que empiezan por gemini usan el proveedor Gemini.
- En caso contrario, se utiliza OpenAI por defecto.
Control de calidad de PDF
Para documentos PDF, puede controlar la calidad de renderizado mediante el parámetro scale:
Valores de escala:
2.0: ~200 DPI (valor por defecto) - Buen equilibrio entre calidad y rendimiento3.0: ~300 DPI - Mayor calidad, recomendado para documentos con texto pequeño4.0: ~400 DPI - Calidad máxima, procesamiento más lento y mayor uso de memoria
Ejemplo:
Consideraciones:
- Valores de escala más altos producen mejor precisión OCR para texto pequeño o complejo.
- Aumenta el tiempo de procesamiento y el consumo de memoria.
- Seleccione en función del tamaño y la complejidad del texto del documento.
Optimizaciones de rendimiento
La herramienta incluye varias optimizaciones para un mejor rendimiento:
- Procesamiento en memoria: las imágenes y los
PDFse convierten aBase64directamente en memoria sin E/S de disco. - Renderizado eficiente de PDF: utiliza pypdfium2 para una conversión rápida de PDF a imagen.
- Limpieza automática: los archivos temporales se eliminan automáticamente tras el procesamiento.
- Procesamiento paralelo de páginas: los
PDFde varias páginas se procesan de forma eficiente.
Ejemplo de uso
Solicitud de reconocimiento de texto desde una imagen/PDF
Suponga que tiene una imagen en /home/user/invoice.png y quiere extraer información de la Factura:
A continuación se muestra una imagen de ejemplo de una factura:
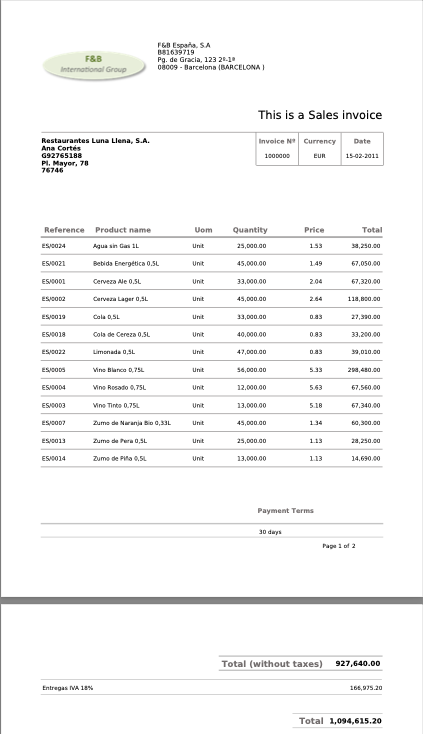
-
Use la herramienta de la siguiente manera:
-
Entrada:
-
Salida:
Output Json{ "company": { "name": "F&B España, S.A.", "tax_id": "B-1579173", "address": "Pg. de Gracia, 123 2-1ª", "city": "08009 - Barcelona (BARCELONA)" }, "invoice": { "title": "This is a Sales invoice", "number": "1000000", "currency": "EUR", "date": "15-02-2011" }, "customer": { "name": "Restaurantes Luna Llena, S.A.", "contact": "Ana Cortes", "phone": "092765188", "address": "Pl. Mayor, 78", "postal_code": "76764" }, "items": [ { "reference": "ES0024", "product_name": "Agua sin Gas 1L", "uom": "Unit", "quantity": 25000, "price": 1.13, "total": 28250.00 }, { "reference": "ES0021", "product_name": "Bebida Energética 0,5L", "uom": "Unit", "quantity": 45000, "price": 1.49, "total": 67050.00 }, { "reference": "ES1000", "product_name": "Cerveza Ale 0,5L", "uom": "Unit", "quantity": 33000, "price": 2.48, "total": 81840.00 }, { "reference": "ES1002", "product_name": "Cerveza Lager 0,5L", "uom": "Unit", "quantity": 45000, "price": 2.64, "total": 118800.00 }, { "reference": "ES0030", "product_name": "Cola de Cereza 0,5L", "uom": "Unit", "quantity": 40000, "price": 0.83, "total": 33200.00 }, { "reference": "ES0032", "product_name": "Limonada 0,5L", "uom": "Unit", "quantity": 40000, "price": 0.83, "total": 33200.00 }, { "reference": "ES0023", "product_name": "Vino Blanco 0,75L", "uom": "Unit", "quantity": 36000, "price": 3.05, "total": 109800.00 }, { "reference": "ES0025", "product_name": "Vino Rosado 0,75L", "uom": "Unit", "quantity": 36000, "price": 5.83, "total": 209880.00 }, { "reference": "ES1004", "product_name": "Vino Tinto 0,75L", "uom": "Unit", "quantity": 36000, "price": 5.07, "total": 182520.00 }, { "reference": "ES0037", "product_name": "Zumo de Naranja 0,5L", "uom": "Unit", "quantity": 45000, "price": 1.13, "total": 50850.00 }, { "reference": "ES1014", "product_name": "Zumo de Piña 0,5L", "uom": "Unit", "quantity": 33000, "price": 1.13, "total": 37390.00 } ], "payment_terms": "30 days", "totals": { "subtotal": 927640.00, "tax": { "rate": "IVA 18%", "amount": 166975.20 }, "total": 1094615.20 } }
-
Uso avanzado: salida estructurada con referencia
Suponga que ha subido una imagen de documento de referencia a la base de datos vectorial de su agente, y ahora quiere extraer datos con un esquema predefinido:
-
Use la herramienta con salida estructurada:
-
Entrada:
-
La herramienta:
- Buscará un documento de referencia similar en la base de datos vectorial
- Usará los marcadores visuales de la referencia para guiar la extracción
- Renderizará el PDF a 300 DPI para una mejor calidad
- Devolverá los datos siguiendo la estructura del esquema
testdocument
-
Salida:
{ "document_id": "DOC-12345", "document_number": "TX-2024-001", "title": "Shipping Manifest", "status": "pending", "priority": "high", "creation_date": "2024-12-16", "owner": { "name": "Jane Smith", "email": "jane@example.com" }, "line_items": [ { "line_number": 1, "item_code": "PROD-A", "description": "Product A", "quantity": 10, "unit_price": 50.00, "line_total": 500.00 } ], "is_active": true, "version": 1 }
-
Uso con configuración de modelo personalizada
Puede configurar un modelo específico para el procesamiento OCR de varias maneras:
Opción 1: Usar el archivo gradle.properties (configuración global)
Abra el archivo gradle.properties y establezca la siguiente propiedad para especificar el modelo para todos los agentes:
Opción 2: Usar la ventana Agente (configuración por agente)
- Abra la ventana Agente en Etendo Classic
- Vaya a la solapa Skills and Tools
- Seleccione la herramienta OCR de la lista
- En el campo Modelo, especifique el modelo usando el formato
provider/modelname: - Para OpenAI:
openai/gpt-4ooopenai/gpt-5-mini - Para Gemini:
google/gemini-1.5-pro - Si se deja vacío, la herramienta usará el modelo por defecto (
openai/gpt-5-mini)
Esto le permite usar distintos modelos para distintos agentes en función de sus necesidades específicas (p. ej., alta precisión para facturas frente a velocidad para recibos).
Encadenamiento de resultados
Note
Recuerde que el resultado de la herramienta puede usarse en otras herramientas; por ejemplo, puede usar el resultado de la herramienta OCR en una herramienta que escriba la información en una base de datos o la envíe a un servicio web.
Este trabajo está licenciado bajo CC BY-SA 2.5 ES por Futit Services S.L.