Etendo BI Extensions Bundle
Javapackage: com.etendoerp.etendobi.extensions
Visión general
En esta sección, el usuario puede encontrar información técnica sobre el bundle Etendo BI Extensions.
Conector de Etendo BI
Javapackage: com.etendoerp.integration.powerbi
En Etendo, es posible crear consultas base y personalizarlas cuando sea necesario. Esto proporcionará información que puede ser utilizada por Power BI.
Para este proceso, se requiere una configuración en segundo plano para crear archivos CSV que se subirán a un servidor. Los archivos utilizarán información de las consultas base preestablecidas y su personalización en caso de que exista alguna.
La siguiente documentación trata sobre los pasos a considerar al configurar esta funcionalidad para crear los archivos CSV.
Requisitos
Para asegurar el correcto funcionamiento del script, siga los pasos a continuación:
Note
Los siguientes pasos solo pueden utilizarse para sistemas operativos Linux.
-
Debe tener instalado rsync en su sistema, ya que es la herramienta que utilizamos para conectarnos al servidor.
-
Asegúrese de tener instalado al menos python3.7 o superior en su sistema. Puede verificar la instalación ejecutando:
Si no está instalado, ejecute:
Y luego verifique que la versión sea correcta. -
Es muy probable que pip3 venga incluido con la instalación de python3. Verifique si está instalado ejecutando:
A continuación, asegúrese de tener una versión actualizada:
Si no está instalado, ejecute:
-
El usuario necesita instalar libpq-dev para asegurar una comunicación fluida y compatibilidad entre nuestro script de python y la base de datos postgresql.
Para instalarlo, ejecute:
-
Las siguientes librerías deben instalarse usando pip3 para que funcionen: psycopg2, pandas y requests. Puede instalarlas ejecutando:
Configuración del módulo Etendo BI Connector
Primero, realice las configuraciones adecuadas desde la ventana Webhooks. Esto permitirá posteriormente que los registros de BI se envíen a la ventana BI Logs Monitor.
Ventana Webhooks
Aplicación > Configuración General > WebHook Events > Webhooks
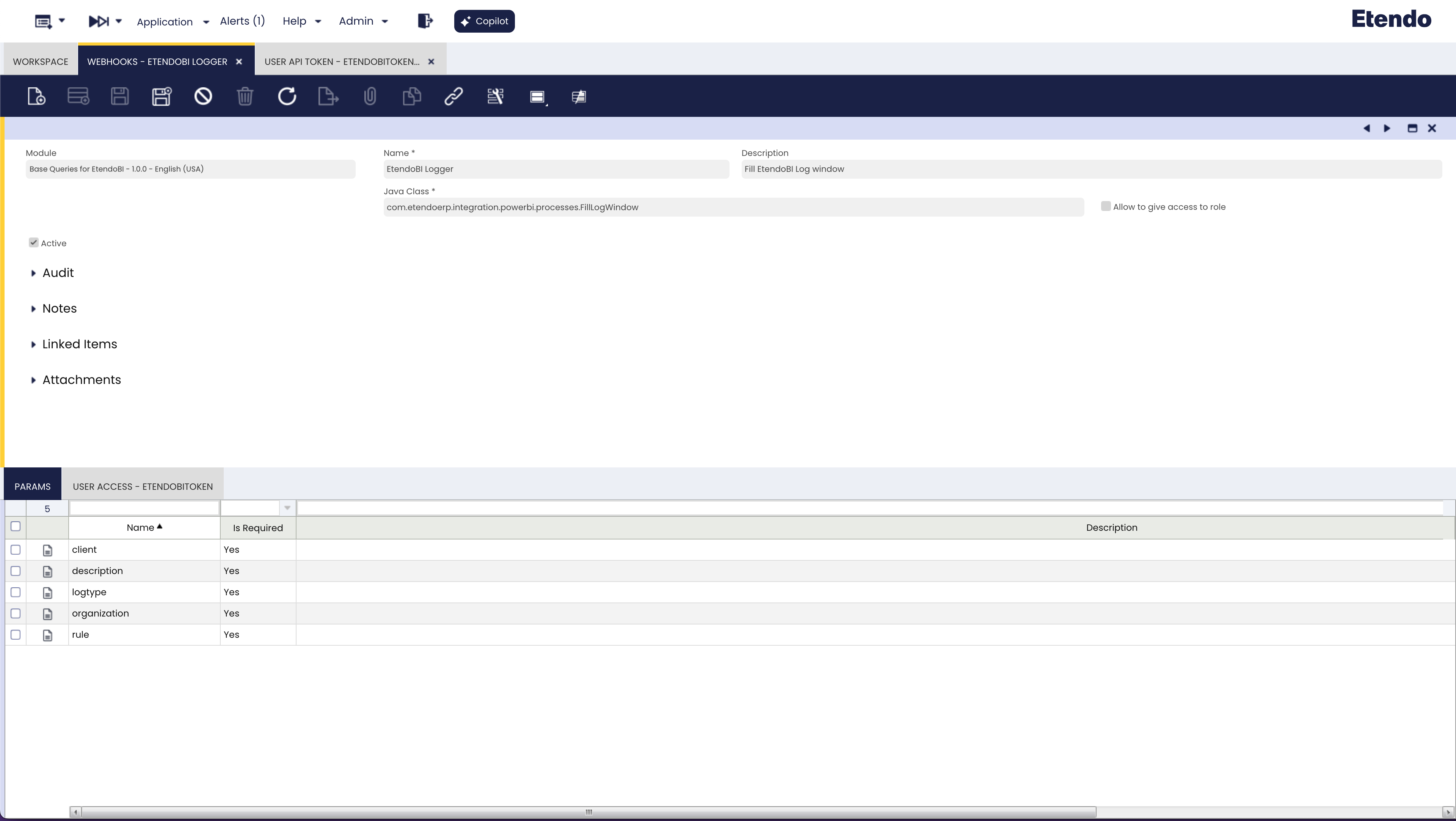
Desde la ventana Webhooks, es necesario crear un nuevo registro y completar los campos requeridos de la siguiente manera:
-
Módulo: Base Queries for EtendoBI
-
Nombre: EtendoBI Logger
-
Descripción: Rellenar la ventana de registro de EtendoBI
-
Clase de evento: Java
-
Java_Class:
com.etendoerp.integration.powerbi.processes.FillLogWindow
Info
Se recomienda encarecidamente tener solo un Webhook para que este módulo funcione correctamente, ya que su funcionalidad no variará. Por ello, es mejor utilizar la organización * para cubrir todas las organizaciones hijas.
En la pestaña Params, deben crearse cuatro registros con los nombres:
-
client
-
description
-
logtype
-
organization
-
rule
Info
Para más información sobre Webhooks, visite Eventos de Webhooks.
Ventana User API Token
Aplicación > Configuración General > WebHook Events > User API Token
A continuación, realice las configuraciones adecuadas desde la ventana User API Token. Aquí, es necesario conceder acceso a un rol de usuario, por lo que debe crearse un token en esta ventana.
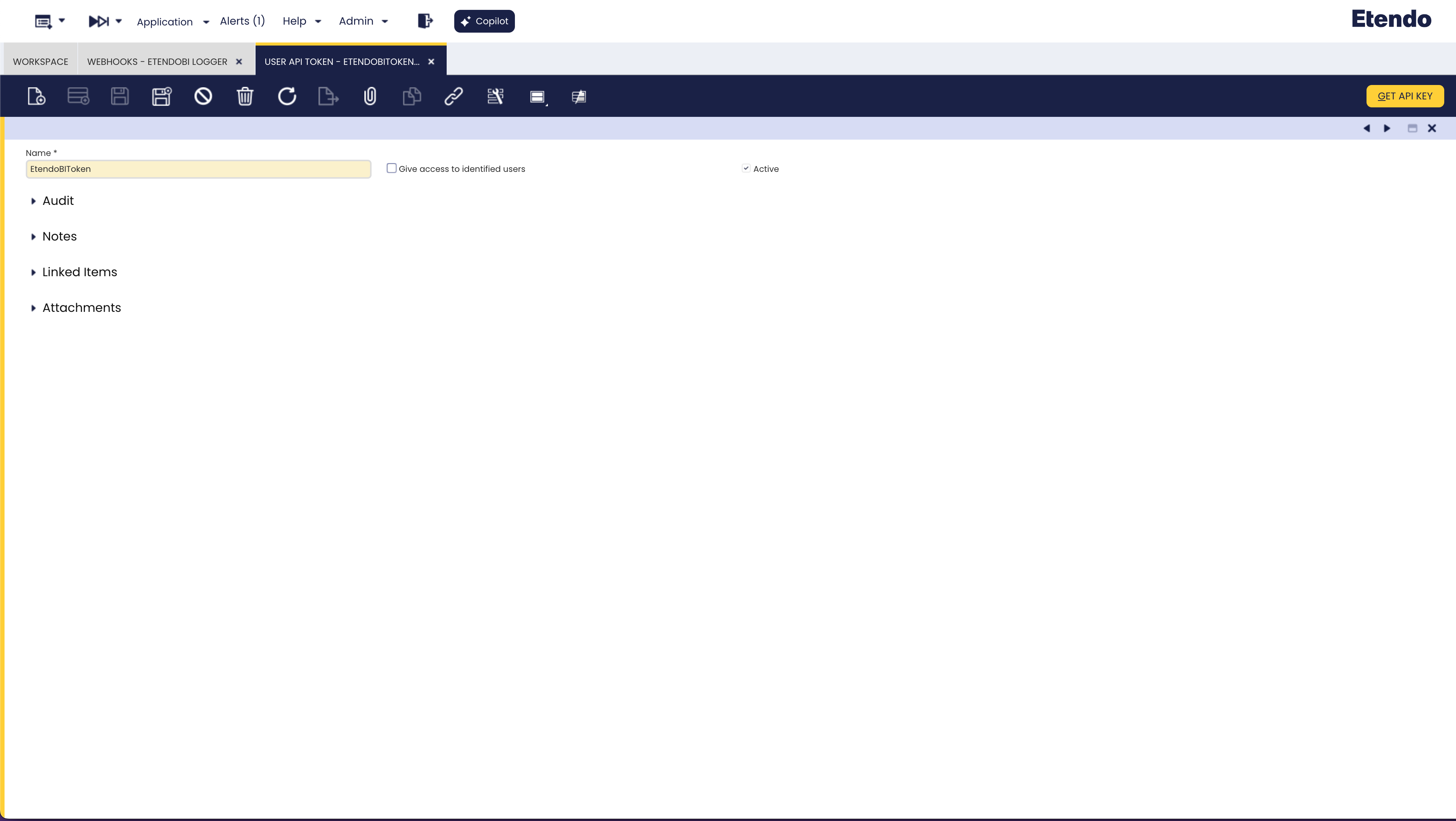
Luego, vuelva a la ventana Webhooks y cree un registro en la pestaña Access para añadir el token generado previamente.

Success
De este modo, el Webhook queda configurado. Ahora, es necesario configurar el módulo EtendoBI Connector.
Ventana BI Connection
Aplicación > Gestión de Datos Maestros > Analysis > BI Connection
En la ventana BI Connection, es necesario crear un registro para especificar la ruta al script de creación de CSV y el Webhook a utilizar. Si el bundle EtendoBI está instalado y la ruta del script no se modificó, el usuario debe utilizar el valor por defecto del campo ‘repository path’. En caso contrario, debe especificarse la ruta correspondiente.
Info
Es importante tener en cuenta que la ruta del repositorio buscará la ruta correspondiente DENTRO de la carpeta WebContent del proyecto.
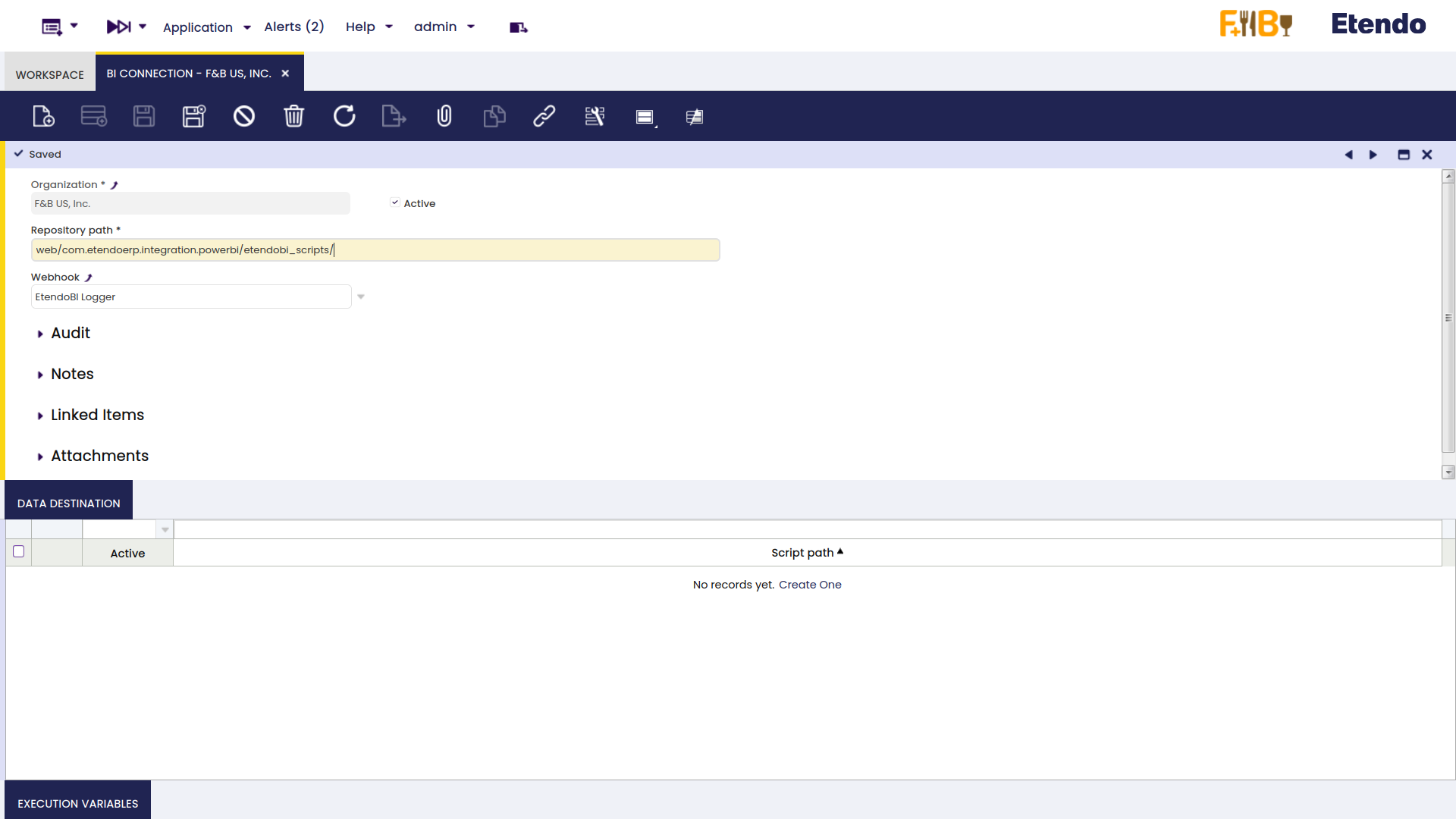
En la pestaña Data Destination, debe especificarse el nombre de archivo del script.
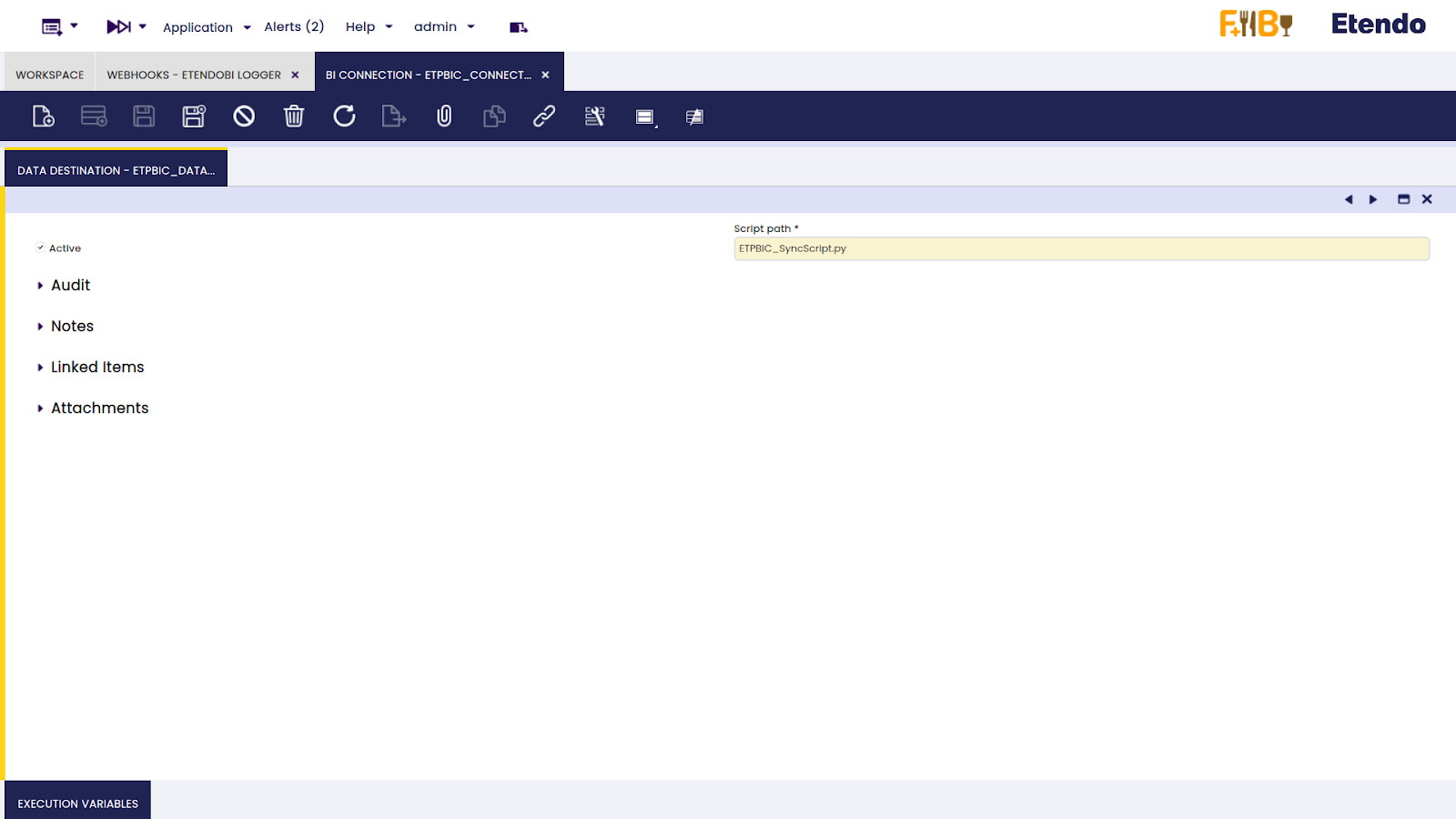
Finalmente, en la pestaña Execution variables, deben crearse algunos registros siendo el campo ‘Variable’:
-
ip: ip del servidor donde se subirán los archivos (obligatorio)
-
client: el nombre de nuestra entidad (obligatorio)
-
user: el usuario utilizado para conectarse al servidor (obligatorio)
-
application_url: url de nuestra aplicación. p. ej. "https://my-domain.cloud/etendo" (obligatorio)
-
port: puerto del servidor al que el usuario se está conectando (por defecto: 22)
-
path: ruta del servidor a donde se enviarán los archivos (por defecto: /)
-
private-key-path: ruta de la clave privada utilizada para la conexión al servidor
-
bbdd_user: nombre usuario de un usuario de solo lectura para acceder a la base de datos
-
bbdd_password: contraseña del usuario de solo lectura
-
csv_separator: delimitador a utilizar en los archivos csv finales (por defecto: |)
private-key-path es la ruta de la clave privada utilizada para la conexión al servidor. Si esta variable no se especifica, el script intentará conectarse sin especificar una clave privada.
En las variables bbdd_user y bbdd_password, introduzca el nombre usuario y la contraseña de un usuario con permisos de solo lectura en la base de datos. Si no se encuentra alguna de estas dos variables, el proceso utilizará las credenciales del superusuario de la base de datos.
Info
No obstante, se recomienda encarecidamente utilizar un usuario con permisos de solo lectura, ya que es una gran medida de seguridad.
Como ejemplo, utilicemos los siguientes valores:

Info
Es importante respetar los nombres especificados para el campo “Variable”.
Además, es importante tener en cuenta que el script va a crear una carpeta con el nombre del valor de la variable “Client”, y contendrá carpetas para cada organización que ejecute el proceso en segundo plano. Por lo tanto, si existen dos BI Connections con el mismo valor “Client”, la última ejecución del proceso sobrescribirá la carpeta.
Por ejemplo, supongamos que existe la Organización A, que tiene como organizaciones hijas a las Organizaciones B y C. Si el usuario necesita tener la misma configuración para ambas, podemos crear una BI Connection usando la Organización A y configurar dos procesos en segundo plano que ejecuten el "Proceso EtendoBI", uno para la Organización B y otro para la Organización C.
Cuando se ejecuta el script, se creará una carpeta con el valor de la variable "Client" en la ventana BI Connection como nombre. Dentro de esa carpeta, se crearán subcarpetas para cada organización (en este caso, A_logs y A_output para la Organización A, y B_logs y B_output para la Organización B).
Ventana Gestión del módulo de Empresa
Aplicación > Configuración General > Organización > Gestión del módulo de Empresa
Para cargar las consultas base de Etendo, vaya a la ventana Gestión del módulo de Empresa, seleccione Base Queries for EtendoBI y luego haga clic en el botón OK.
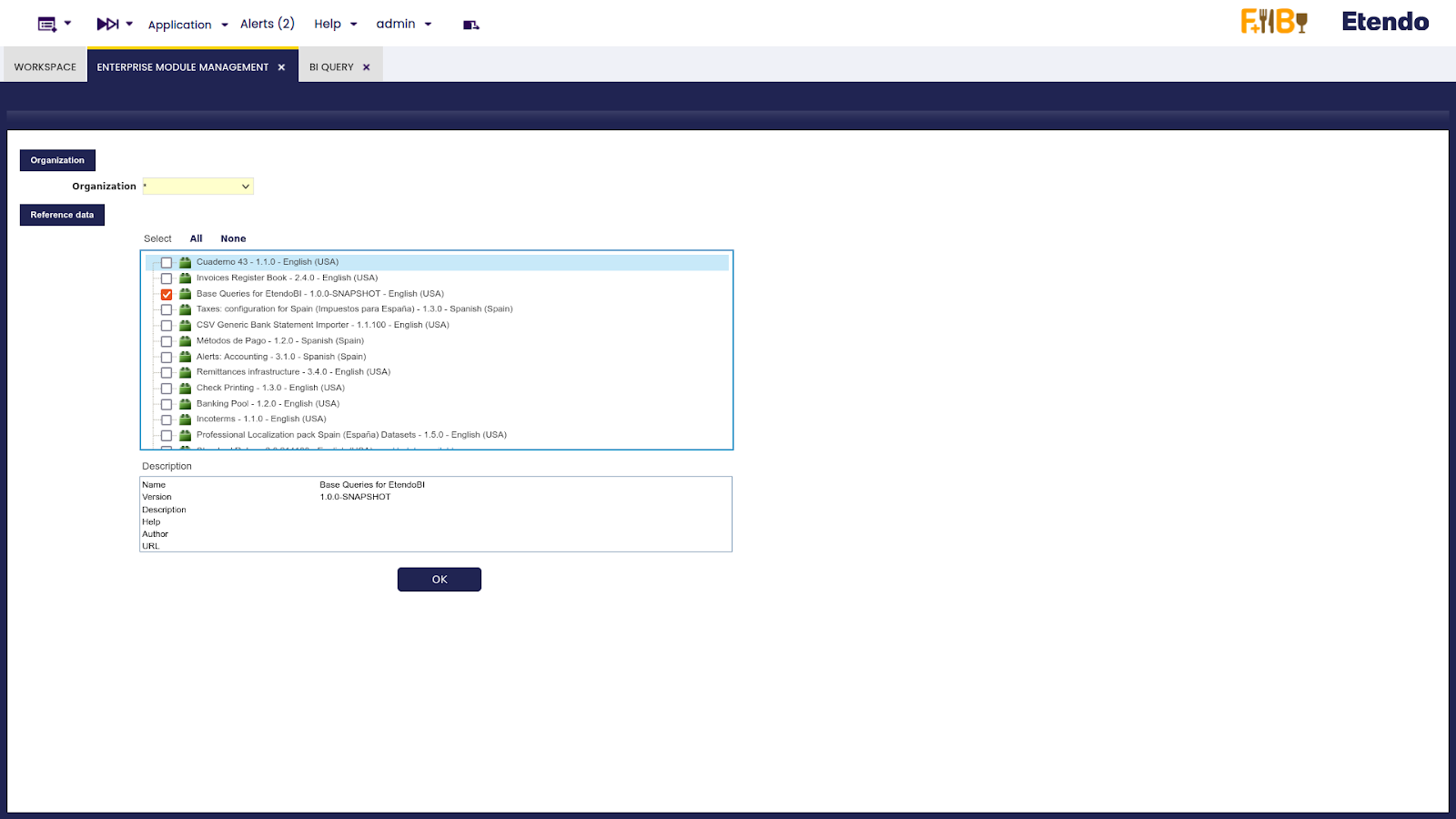
Ventana BI Query
Aplicación > Gestión de Datos Maestros > Analysis > BI Query
Después de eso, las consultas base de Etendo deberían cargarse correctamente en la ventana BI Query.
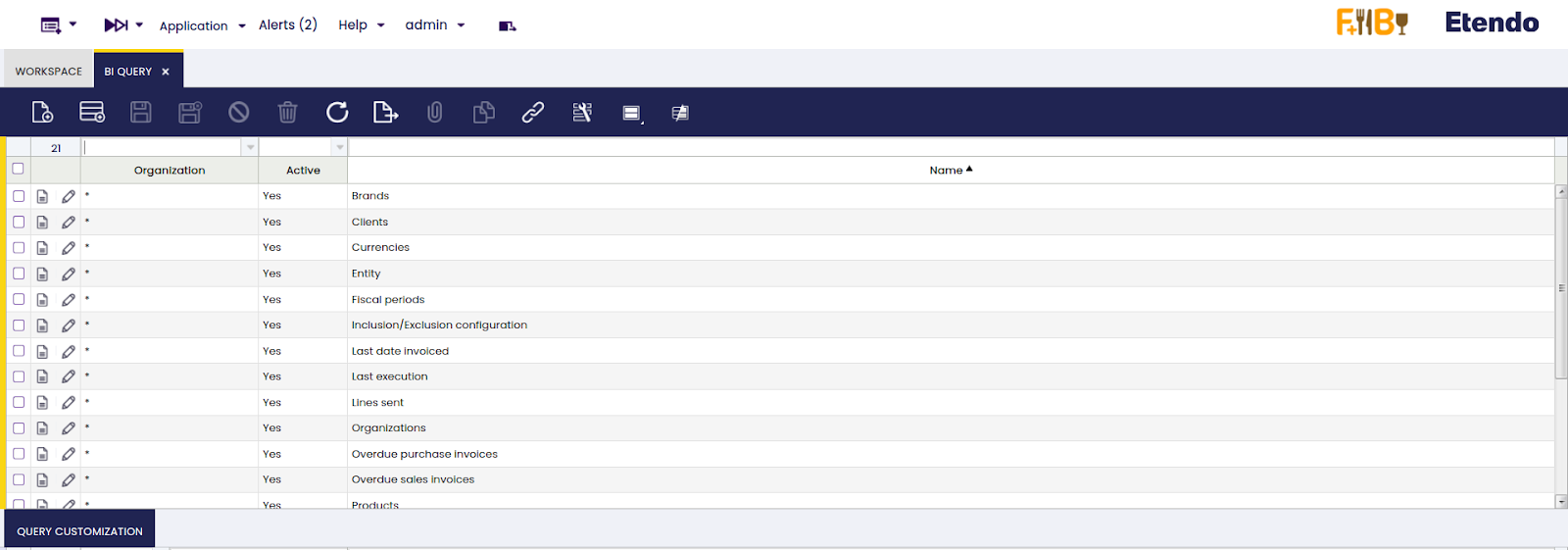
Hay varios puntos a considerar al gestionar consultas en este módulo.
- Requisito de clave primaria: cada consulta base debe tener su clave primaria como primera columna. Esto es crucial, ya que en el script se asume que la primera columna es el identificador.
Warning
No cumplir con esto puede dar lugar a una salida incorrecta, registros duplicados y una cantidad inmensa de filas.
-
Columna Client en la consulta base: cada consulta base debe incluir la columna
ad_client_id, con el alias “ClientID” -
Columna Organization en la consulta base: cada consulta base debe incluir la columna
ad_org_id, con el alias “OrgID” -
Personalización de consulta personalizada: la personalización de la consulta también debe incluir la clave primaria (que es la misma que la de la consulta base, ya que la personalización se realiza sobre la misma tabla) con el MISMO ALIAS que la consulta base.
Warning
No respetar esto puede provocar un mapeo incorrecto entre los resultados de la consulta base y su personalización, dando como resultado una salida incorrecta.
Veamos un ejemplo de una consulta base y una personalización correctas.
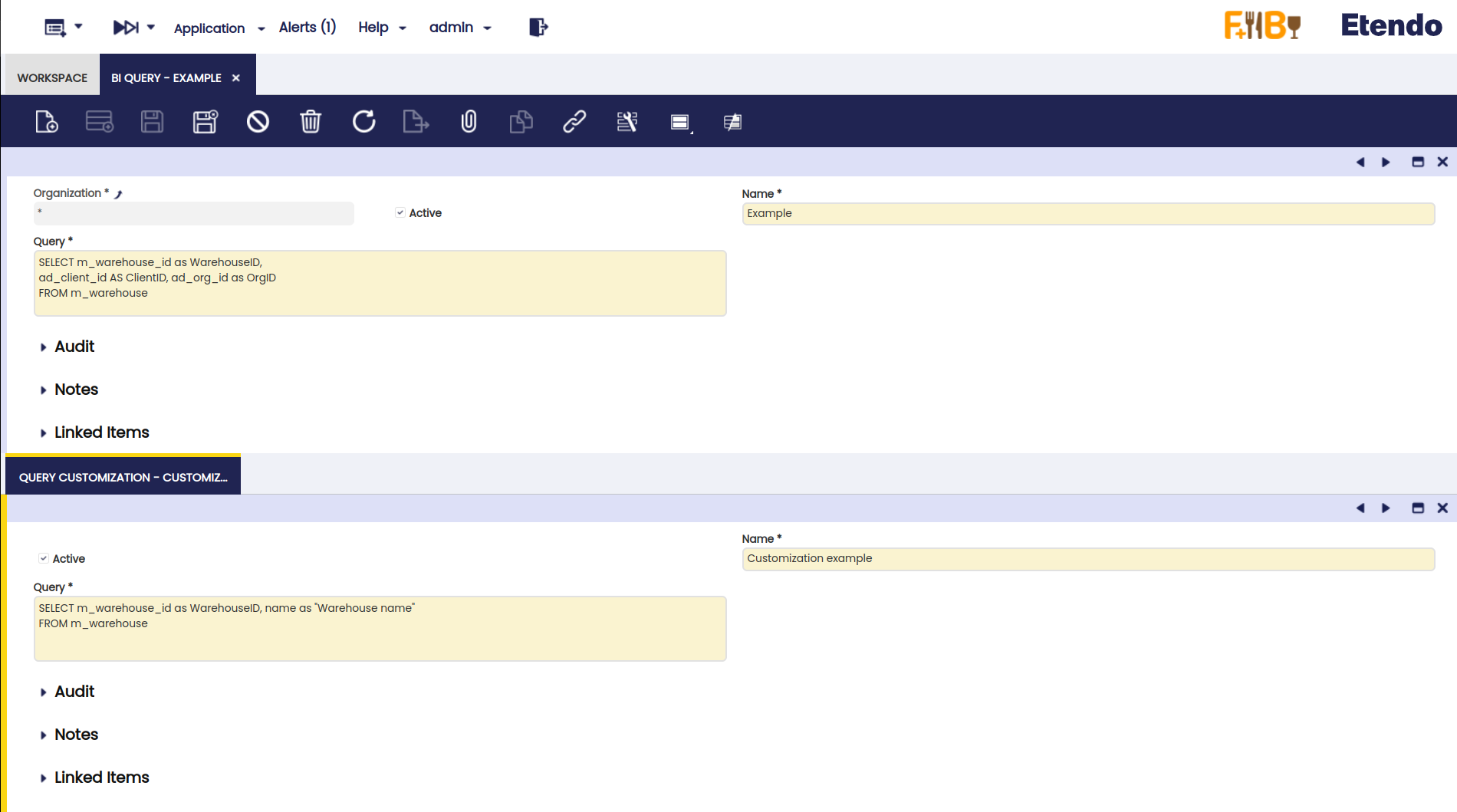
En este caso, como consulta base hay tres columnas. En su personalización, hay una nueva columna “name”.
Info
Tenga en cuenta que hay tres columnas obligatorias en la consulta base, con el alias correcto para la columna ad_client_id y ad_org_id. Es importante asegurarse de que los alias “ClientID” y “OrgID” se establecen SIN comillas dobles. Además, no debe haber más de un espacio entre la palabra clave “as”.
En la consulta de personalización, a pesar del requisito de tener la clave primaria con el mismo alias que la consulta base, no es necesario que sea la primera columna. En este caso, si en lugar de tener:
Tenemos:
El resultado será exactamente el mismo.
El script ejecuta la consulta base y luego fusiona la personalización, utilizando ambas claves primarias para mapear las filas.
Si una consulta base tiene una personalización, el script crea tres CSV diferentes.
-
Un archivo CSV que contiene el resultado de la consulta base. Este archivo CSV tiene el prefijo
EBI_si es una consulta base de Etendo. Si es una consulta base de entidad, tiene como prefijo las tres primeras letras del valor de la variable “Client” que se estableció anteriormente. -
Un archivo CSV con el prefijo
BASE_, que contiene las columnas de la consulta base, pero si la personalización sobrescribe alguno de estos valores, se sobrescribirán con los valores de la personalización. En este caso, el archivo CSVBASE_será el mismo que la consulta base, ya que la personalización no sobrescribe ningún valor de las columnas de la consulta base. -
Un archivo CSV con el prefijo
FULL_, que incluye tanto las columnas de la consulta base como cualquier columna adicional añadida en la personalización. En el ejemplo dado, el archivo CSVFULL_contendrá la columna adicional “Warehouse Name”.
Más adelante, al final de la configuración, este ejemplo de consulta se ejecutará para analizar los archivos CSV generados.
Info
Es importante tener en cuenta que solo debe haber una personalización por consulta base. También debe quedar claro que no es posible añadir restricciones a la personalización para eliminar filas de la consulta base. En su lugar, la personalización permite añadir o sobrescribir columnas en la consulta original, utilizando la clave primaria para mapear los registros.
Todas las consultas base deben contener las columnas ad_client_id y ad_org_id, con los alias “ClientID” y “OrgID” (sin distinción entre mayúsculas y minúsculas).
Warning
Si una consulta no tiene estas columnas con sus alias, producirá un error y será ignorada.
Ventana Procesamiento de Peticiones
Aplicación > Configuración General > Planificador de procesos > Procesamiento de Peticiones
Una vez realizada la configuración de consultas, vaya a la ventana Procesamiento de Peticiones, cree un nuevo registro, seleccione el Proceso EtendoBI en el campo de proceso y planifíquelo.
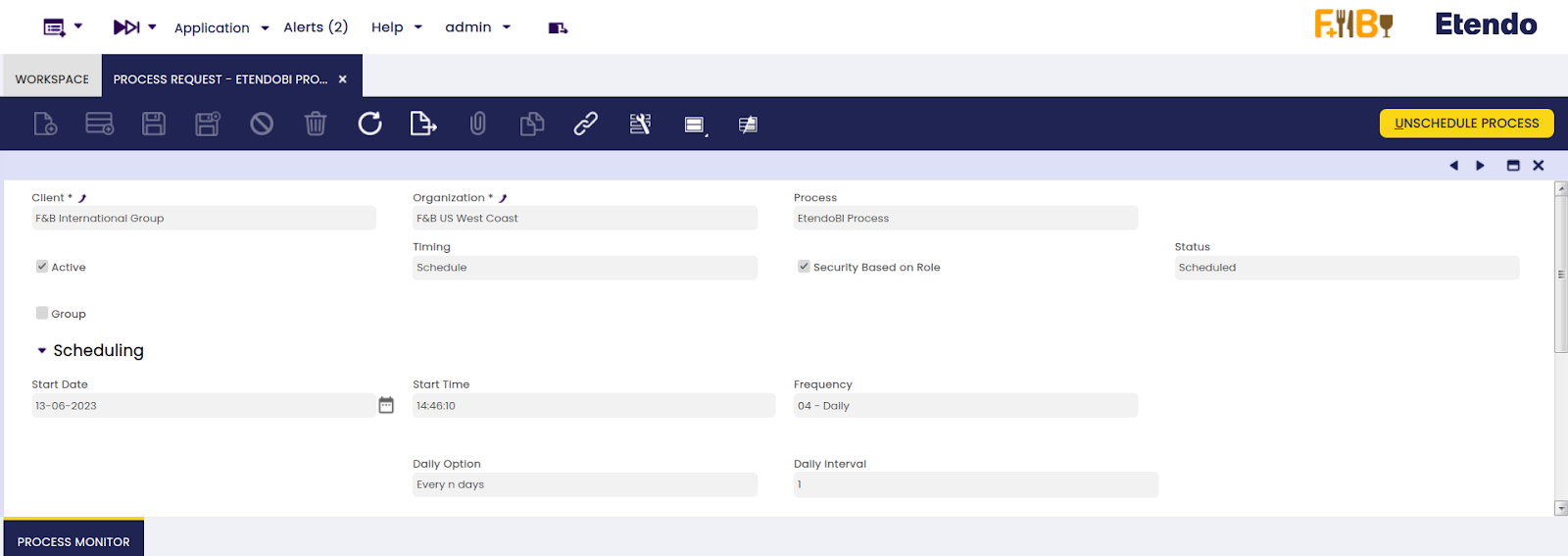
El alcance de la recopilación de datos realizada por las consultas se basa en la organización que configuró el proceso en segundo plano. En otras palabras, todos los datos obtenidos se filtran por la entidad y la organización que configuró el proceso en segundo plano, y NO por la organización utilizada en la ventana BI Connection. Si la organización no tiene una configuración en la BI Connection, Etendo buscará la configuración en una de sus organizaciones padre, pero el alcance de los datos seguirá siendo el mismo (ella misma y sus organizaciones hijas).
Info
Si la organización que configuró el proceso en segundo plano no tiene una BI Connection y tampoco se encuentra una BI Connection para sus organizaciones padre, el proceso no se ejecutará.
El proceso nunca buscará una BI Connection en las organizaciones hijas de la que se configuró en el proceso en segundo plano.
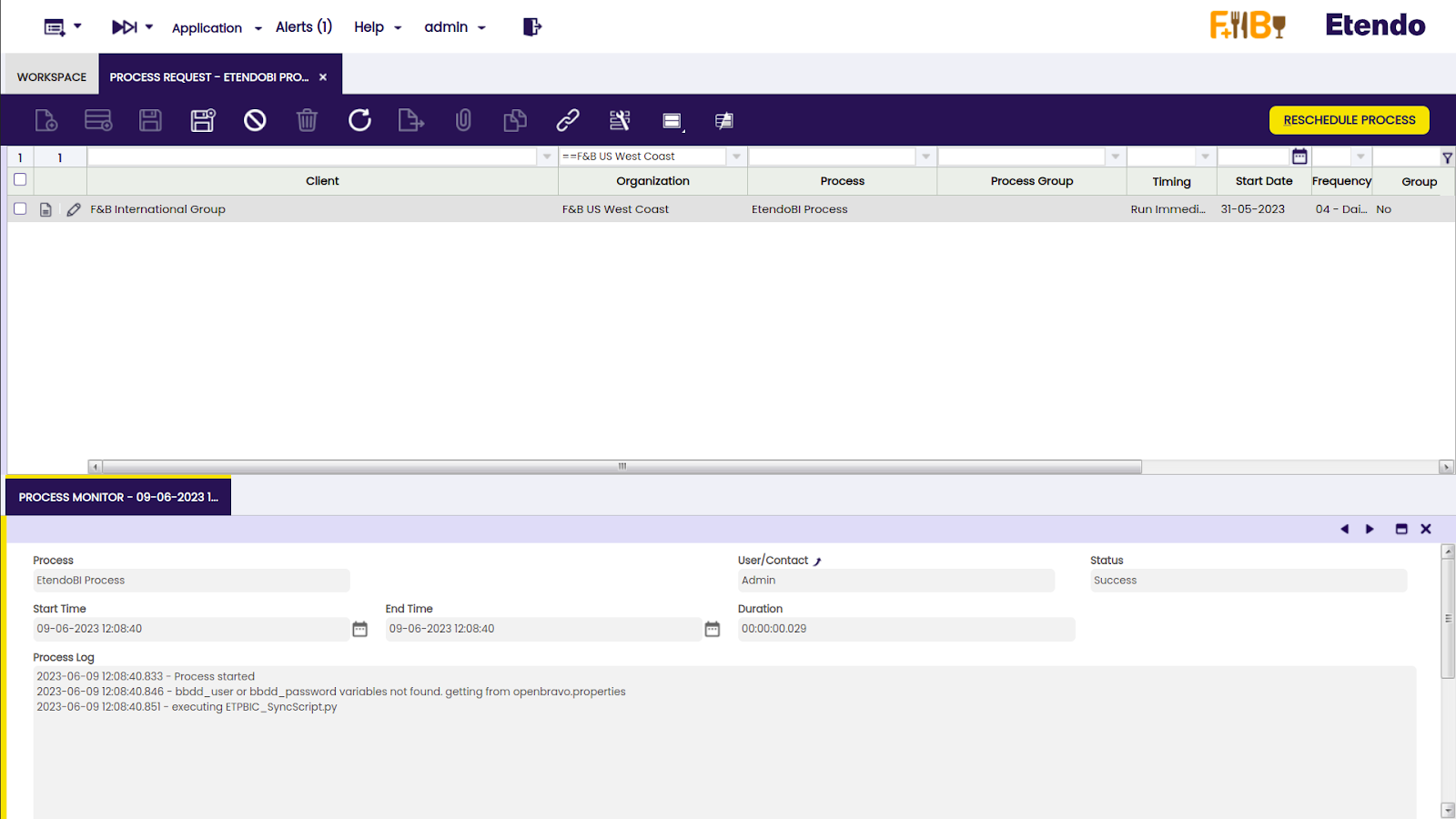
En la pestaña Monitor de Procesos, se muestra el estado Success en el nuevo registro que aparece cuando se ejecuta el proceso. Es importante saber que este proceso ejecuta nuestro script de python, por lo que, si no hubo problemas hasta la ejecución del script de python, devolverá el estado success independientemente de si el script de python falla.
Ventana BI Logs Monitor
Aplicación > Gestión de Datos Maestros > Analysis > BI Logs Monitor
El proceso de ejecución puede comprobarse en la ventana BI Logs Monitor.
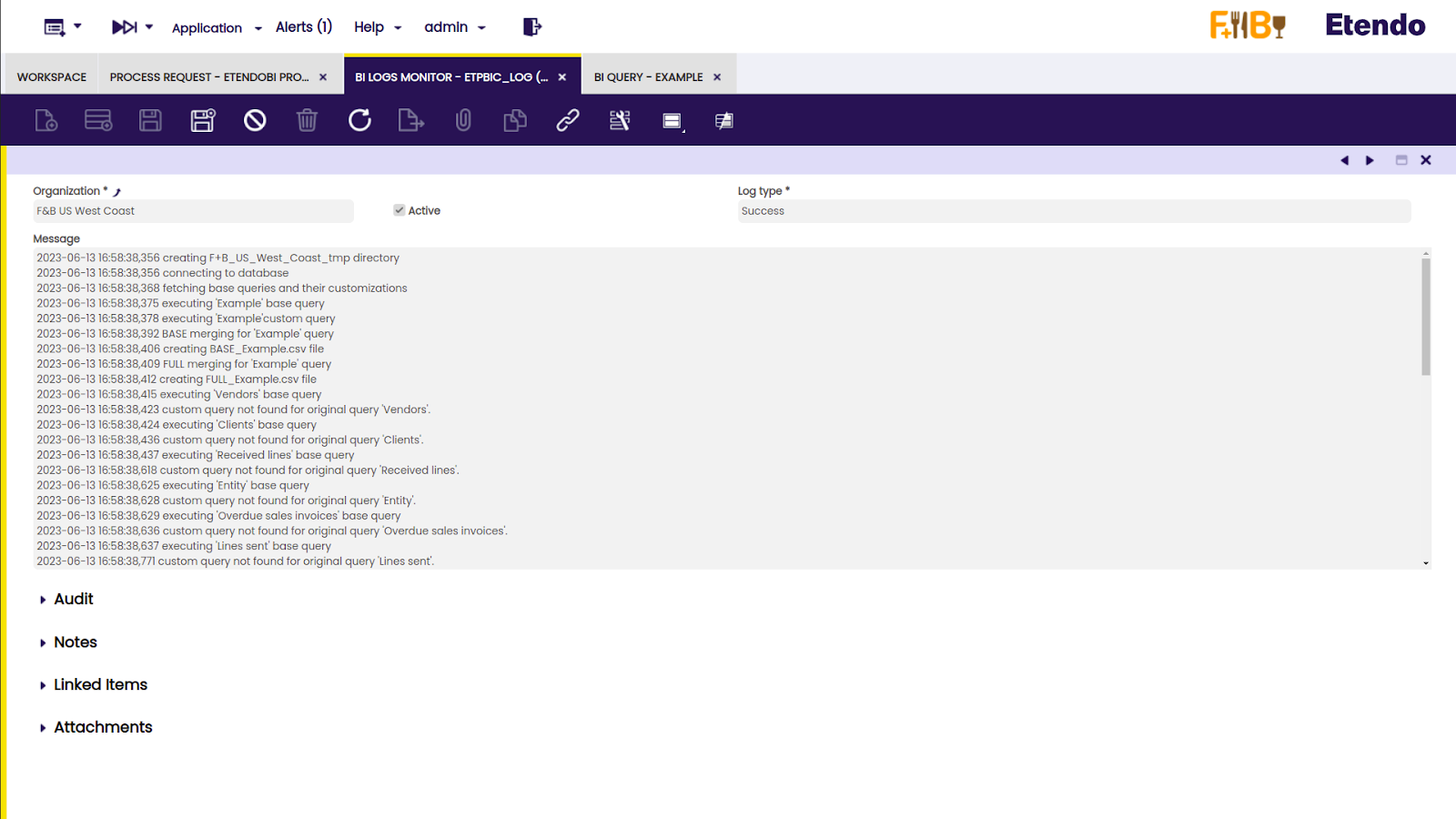
En esta imagen de ejemplo, puede verse la información sobre la ejecución del script.
Si no se crearon registros en la ventana Logs después de la ejecución del script, es posible que el error se produjera en la sincronización de los archivos con el servidor. El usuario puede comprobarlo revisando los archivos de log de rsync creados en el sistema de archivos.
Tras la ejecución del proceso, deberían crearse dos nuevos directorios en el sistema de archivos. Uno contendrá los archivos de logs, uno para la ejecución de rsync que contendrá información sobre la subida de archivos al servidor; y otro archivo llamado syncScript.log.{datetime}, que contendrá información sobre la ejecución del script (la mayor parte de esta información puede verse en la ventana BI Logs Monitor, pero si por cualquier motivo la ventana no puede recibir esta información, debería poder verse usando este archivo .log).
En este ejemplo, en la ruta donde está ubicado el script, debería crearse un nuevo directorio llamado “Etendo”. Dentro de él, debería haber dos carpetas para la organización que configuró el proceso en segundo plano (F&B US West Coast).
drwxrwxr-x 1 <user> <group> 9,1K jun 8 16:52 ETPBIC_SyncScript.py
drwxrwxr-x 4 <user> <group> 4,0K jun 8 17:39 Etendo/
Dentro de la carpeta Etendo/, tenemos:
drwxrwxr-x 2 <user> <group> 4,0K jun 8 16:54 F+B_US_West_Coast_logs/
drwxrwxr-x 2 <user> <group> 4,0K jun 8 16:54 F+B_US_West_Coast_output/
El directorio de salida contendrá todos los CSV que deberían haberse subido al servidor.
Info
Recuerde que la carpeta principal se crea usando el prefijo de la variable “Client” que se establece en la ventana BI Connection. Si dos conexiones tienen el mismo valor para la variable “Client”, estos directorios se sobrescribirán.
Este es el contenido de los archivos Ete_Example.csv y BASE_Example.csv:
Info
Recuerde que, dado que no se está sobrescribiendo ninguna columna, estos archivos son iguales.

Por otro lado, este es el contenido de FULL_Example.csv:

Warning
Asegúrese de tener los permisos correspondientes para conectarse a Files, ya que una configuración incorrecta puede provocar un error.
This work is licensed under CC BY-SA 2.5 ES by Futit Services S.L..